Redis介绍(缓存)
Redis安装 编译工具安装
1 2 yum -y install gcc automake autoconf libtool make #gcc编译环境
关于yum命令
yum( Yellow dog Updater, Modified)是一个在Fedora和RedHat以及SUSE中的Shell前端软件包管理器。
基於RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软体包,无须繁琐地一次次下载、安装
相关链接
linux安装Redis
1 2 3 4 5 6 7 8 9 mkdir –p /usr/local/src/rediscd /usr/local/src/rediscd redis-5.0.0
1 2 3 4 5 6 7 8 9 redis-server bind 127.0.0.1 ::1即可
1 2 3 redis-server –v
1 2 redis-cli
redis常用命令 测试服务是否正常 1 2 3 4 5 6 7 8 9 10 11
redis场景命令回复 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 test 123command 'TEST' integer ) 1test "test_incr" "test"
Redis退出
1 2 3 4 exit
基础命令 keys
字符串类型是redis中最基本的数据类型,它能存储任何形式的字符串,包括二进制数据。可以存储JSON化的对象、字节数组等。一个字符串类型键允许存储的数据最大容量是512MB。
赋值与取值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 127.0.0.1:6379> keys *set )set test 123set test1 ab"test1" "test" test "123" "abc"
keys通配符
1 2 3 4 5 6 7 8 KEYS *test [_]*
select
redis默认支持16个数据库,对外都是以一个从0开始的递增数字命名,可以通过参数database来修改默认数据库个数。客户端连接redis服务后会自动选择0号数据库,可以通过select命令更换数据库,例如选择1号数据库:
1 2 3 4 127.0.0.1:6379>SELECT 1test
注意
Redis不支持自定义数据库名称。
Redis不支持为每个数据库设置访问密码。
Redis的多个数据库之间不是安全隔离的,FLUSHALL命令会清空所有数据库的数据。
clear
exists
1 2 3 4 5 6 1) "name" "num" integer ) 1integer ) 0
del
1 2 3 4 5 6 7 127.0.0.1:6379> keys *"name" "num" integer ) 2set )
type
获得键值的数据类型,返回值可能是string(字符串)、hash(散列类型)、list(列表类型)、set(集合类型)、zset(有序集合类型)。
1 2 3 4 5 6 7 127.0.0.1:6379> keys *"test1" "test" type test type test1
help
1 2 3 4 5 6 127.0.0.1:6379> help type type stored at key
flushall/flushdb
清除数据库
flushall清除所有数据库
flushdb清除当前数据库
字符串操作
设置num为key
递增递减
incr num 为num递增1incrby num 3 为num递增3如果num不存在,则自动会创建,如果存在自动+1
decr num 为num递减1decrby num 3 为num递减3
浮点递增
浮点递增会有精度问题,2.8.7注意在新版本中已经修正了这个浮点精度问题。3.0.7
incrbyfloat num 0.3 为num递增0.3
字符串拼接
向尾部追加值。如果键不存在则创建该键,其值为写的value,即相当于SET key
1 2 3 4 5 6 7 8 9 10 11 127.0 .0 .1 :6379 > keys *1 ) "num" 2 ) "test1" 3 ) "test" 127.0 .0 .1 :6379 > get test"123" 127.0 .0 .1 :6379 > append test "abc" 6 127.0 .0 .1 :6379 > get test"123abc" 127.0 .0 .1 :6379 >
返回键值字符串长度
1 2 3 4 5 127.0 .0 .1 :6379 > set name dsfjawoeijfoaewjf;aijefj127.0 .0 .1 :6379 > strlen name (integer) 24
多key赋值
同时设置/获取多个键值
语法:
MSET keyvalue [key value …]MGET key [key …]
1 2 3 4 5 6 7 127.0 .0 .1 :6379 > mset a 1 b 2 c 3 127.0 .0 .1 :6379 > mget a b c1 ) "1" 2 ) "2" 3 ) "3" 127.0 .0 .1 :6379 >
Redis生存时间
expire
Redis在实际使用过程中更多的用作缓存,然而缓存的数据一般都是需要设置生存时间的,即到期后数据自动销毁
语法:EXPIRE key seconds
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 127.0 .0 .1 :6379 > flushall127.0 .0 .1 :6379 > set bomb tnt127.0 .0 .1 :6379 > expire bomb 10 1 127.0 .0 .1 :6379 > ttl bomb (integer) 5 127.0 .0 .1 :6379 > ttl bomb (integer) 3 127.0 .0 .1 :6379 > ttl bomb (integer) 3 127.0 .0 .1 :6379 > ttl bomb (integer) 2 127.0 .0 .1 :6379 > ttl bomb (integer) 1 127.0 .0 .1 :6379 > ttl bomb (integer) -2 127.0 .0 .1 :6379 > ttl bomb (integer) -2
TTL查看key的剩余时间,当返回值为-2时,表示键被删除。
当 key 不存在时,返回 -2 。当 key 存在但没有设置剩余生存时间时,返回 -1 。 否则,以毫秒为单位,返回
注意:在 Redis 2.8以前,当 key 不存在,或者 key 没有设置剩余生存时间时,命令都返回 -1 。
persist
1 2 3 4 5 6 7 8 9 10 127.0 .0 .1 :6379 > set bomb tnt127.0 .0 .1 :6379 > expire bomb 60 1 127.0 .0 .1 :6379 > ttl bomb (integer) 49 127.0 .0 .1 :6379 > persist bomb (integer) 1 127.0 .0 .1 :6379 > ttl bomb (integer) -1
pexpire
语法:pexpire key milliseconds
设置生存时间为毫秒,可以做到更精确的控制。
可用于秒杀业务
1 2 3 4 5 6 7 8 9 10 127.0 .0 .1 :6379 > set bomb tnt127.0 .0 .1 :6379 > pexpire bomb 10000 1 127.0 .0 .1 :6379 > ttl bomb (integer) 6 127.0 .0 .1 :6379 > ttl bomb (integer) 3 127.0 .0 .1 :6379 > ttl bomb (integer) -2
Redis的hash使用
假设有User对象以JSON序列化的形式存储到redis中,User对象有id、username、password、age、name等属性,存储的过程如下:
User对象->json(string)->redis
如果在业务上只是更新age属性,则需要Redis数据类型的散列类型hash
散列类型存储了字段(field)和字段值的映射,但字段值只能是字符串 ,不支持其他类型,也就是说,散列类型不能嵌套其他的数据类型。一个散列类型可以包含最多232-1个字段。
hash基础命令
hget、hset、hincrby、hmset、hmget、hexists、hdel增删改查字符串操作等与普通字符串类型一致,但取值或操作时需考虑字段值的添加
语法:基础命令 键 字段 (值)
案例:hincrby person age 2 或 hlen person name
hgetall
hlen
hkeys/hvals
Jedis演示 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 package cn.redis;import java.util.Map;import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisPool;import redis.clients.jedis.JedisPoolConfig;public class JedisPoolDemoCMD {public static void main (String[] args) {JedisPoolConfig jedisPoolConfig = new JedisPoolConfig ();50 );JedisPool jedisPool = new JedisPool (jedisPoolConfig, "127.0.0.1" , 6379 );Jedis jedis = jedisPool.getResource();"USER_1" , "username" , "zhangsan" );"USER_1" , "password" , "123456" );"USER_1" );for (Map.Entry<String, String> entry : val.entrySet()) {" " + entry.getValue());
1 2 3 4 5 6 7 8 9 10 127.0 .0 .1 :6379 > hgetall USER_11 ) "username" 2 ) "zhangsan" 3 ) "password" 4 ) "123456" 127.0 .0 .1 :6379 > hgetall user_1 (empty list or set) 127.0 .0 .1 :6379 >
Redis的List使用
一个列表最多可以包含232-1个元素(4294967295,每个表超过近43亿个元素)
Redis的list类型其实就是一个每个子元素都是string类型的双向链表。可以通过push,pop操作从链表的头部或者尾部添加删除元素。这使得list既可以用作栈,也可以用作队列。
有意思的是list的pop操作还有阻塞版本的,当我们[lr]pop一个list对象时,如果list是空,或者不存在,会立即返回nil。但是阻塞版本的b[lr]pop则可以阻塞,当然可以加超时时间,超时后也会返回nil。 为什么要阻塞版本的pop呢,主要是为了避免轮询 。举个简单的例子如果我们用list来实现一个工作队列。执行任务的thread可以调用阻塞版本的pop去获取任务这样就可以避免轮询去检查是否有任务存在。当任务来时候工作线程可以立即返回,也可以避免轮询带来的延迟。
List的基本命令
lpush
在key对应list的头部添加字符串元素
1 2 3 4 5 6 7 8 9 10 127.0 .0 .1 :6379 > lpush career teacher (integer) 1 127.0 .0 .1 :6379 > lpush career doctor (integer) 2 127.0 .0 .1 :6379 > lpush career student (integer) 3 127.0 .0 .1 :6379 > lrange career 0 -1 1 ) "student" 2 ) "doctor" 3 ) "teacher"
rpush
在key对应list的尾部添加字符串元素(r是右边l是左边)
1 2 3 4 5 6 7 8 9 10 127.0 .0 .1 :6379 > rpush career worker (integer) 4 127.0 .0 .1 :6379 > rpush career engnieer (integer) 5 127.0 .0 .1 :6379 > lrange career 0 -1 1 ) "student" 2 ) "doctor" 3 ) "teacher" 4 ) "worker" 5 ) "engnieer"
lrange
查看list(start end) – 0到-1可以查看所有内容
1 2 3 4 5 6 127.0 .0 .1 :6379 > lrange career 0 -1 1 ) "student" 2 ) "doctor" 3 ) "teacher" 4 ) "worker" 5 ) "engnieer"
del
同基本String类型操作删除这个list
linsert
在key对应list的特定位置之前或之后添加字符串元素
1 2 3 4 5 6 7 8 9 127.0 .0 .1 :6379 > LINSERT career after worker worker1 (integer) 6 127.0 .0 .1 :6379 > lrange career 0 -1 1 ) "student" 2 ) "doctor" 3 ) "teacher" 4 ) "worker" 5 ) "worker1" 6 ) "engnieer"
lset
设置list中指定下标的元素值
当下标中有元素则会替换
负数从尾部计数,第一个数为-1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 127.0 .0 .1 :6379 > lrange career 0 -1 1 ) "student" 2 ) "doctor" 3 ) "teacher" 4 ) "worker" 5 ) "worker1" 6 ) "engnieer" 127.0 .0 .1 :6379 > lset career 4 worker(set)127.0 .0 .1 :6379 > lrange career 0 -1 1 ) "student" 2 ) "doctor" 3 ) "teacher" 4 ) "worker" 5 ) "worker(set)" 6 ) "engnieer"
lrem
根据count参数按顺序从删除与参数value相同的值
count>0顺序删除
count<0逆序删除
count=0删除所有
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 127.0 .0 .1 :6379 > lrange career 0 -1 1 ) "student" 2 ) "doctor" 3 ) "teacher" 4 ) "worker" 5 ) "salier" 6 ) "engnieer" 7 ) "worker" 8 ) "worker" 9 ) "worker" 10 ) "worker" 127.0 .0 .1 :6379 > lrem career -4 worker4 127.0 .0 .1 :6379 > lrange career 0 -1 1 ) "student" 2 ) "doctor" 3 ) "teacher" 4 ) "worker" 5 ) "salier" 6 ) "engnieer"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 redis 127.0 .0 .1 :6379 > rpush mylist8 "one" 1 127.0 .0 .1 :6379 > rpush mylist8 "two" 2 127.0 .0 .1 :6379 > rpush mylist8 "three" 3 127.0 .0 .1 :6379 > rpush mylist8 "four" 4 127.0 .0 .1 :6379 > ltrim mylist8 1 -1 127.0 .0 .1 :6379 > lrange mylist8 0 -1 1 ) "two" 2 ) "three" 3 ) "four"
lpop
从list的头部(左边)删除元素并返回删除的值
1 2 3 4 5 6 7 8 9 127.0 .0 .1 :6379 > lrange career 0 -1 1 ) "student" 2 ) "doctor" 3 ) "teacher" 4 ) "worker" 5 ) "salier" 6 ) "engnieer" 127.0 .0 .1 :6379 > lpop career"student"
rpop
从list的尾部(右边)删除元素,并返回删除元素
1 2 3 4 5 6 7 8 9 10 11 127.0 .0 .1 :6379 > lrange career 0 -1 1 ) "student2" 2 ) "student" 3 ) "doctor" 4 ) "teacher" 5 ) "worker" 6 ) "salier" 7 ) "engnieer" 8 ) "student3" 127.0 .0 .1 :6379 > rpop career"student3"
1 2 127.0 .0 .1 :6379 > llen career (integer) 7
1 2 3 4 127.0 .0 .1 :6379 > lindex career 3 "teacher" 127.0 .0 .1 :6379 > llen career (integer) 7
rpoplpush
从第一个list尾部取出数据从头放到第二个list中,并返回删除的数据值
1 2 3 4 127.0 .0 .1 :6379 > RPOPLPUSH career newcareer"engnieer" 127.0 .0 .1 :6379 > lrange newcareer 0 -1 1 ) "engnieer"
利用链表形成安全的消息队列 RPOPLPUSH命令实现安全消息队列。Redis链表经常会被用于消息队列的服务,以完成多程序之间的消息交换。假设一个应用程序正在执行LPUSH操作向链表中添加新的元素,我们通常将这样的程序称之为”生产者(Producer)”,而另外一个应用程序正在执行RPOP操作从链表中取出元素,我们称这样的程序为”消费者(Consumer)”。如果此时,消费者程序在取出消息元素后立刻崩溃,由于该消息已经被取出且没有被正常处理,那么我们就可以认为该消息已经丢失,由此可能会导致业务数据丢失,或业务状态的不一致等现象的发生。然而通过使用RPOPLPUSH命令,消费者程序在从主消息队列中取出消息之后再将其插入到备份队列中,直到消费者程序完成正常的处理逻辑后再将该消息从备份队列中删除。同时我们还可以提供一个守护进程,当发现备份队列中的消息过期时,可以重新将其再放回到主消息队列中,以便其它的消费者程序继续处理。
Redis的set使用
Redis灾难恢复模式 rdb和aof比较
RDB
AOF
fork一个进程,遍历hashtable,利用copy onwrite,把整个db dump保存下来。save,shutdown, slave 命令会触发这个操作。
把写操作指令,持续的写到一个类似日志文件里。(类似于从postgresql等数据库导出sql一样,只记录写操作)
粒度比较大,如果save, shutdown, slave 之前crash了,则中间的操作没办法恢复。
粒度较小,crash之后,只有crash之前没有来得及做日志的操作没办法恢复。
两种区别就是,一个是持续的用日志记录写操作,crash(崩溃)后利用日志恢复;一个是平时写操作的时候不触发写,只有手动提交save命令,或者是shutdown关闭命令时,才触发备份操作。
选择的标准,就是看系统是愿意牺牲一些性能,换取更高的缓存一致性(aof),还是愿意写操作频繁的时候,不启用备份来换取更高的性能,待手动运行save的时候,再做备份(rdb)。rdb这个就更有些 最终一致性(eventually consistent)的意思了。
性能比较
测试方法是用java写的脚本对redis数据库进行写入,看写入速度。
100000/300000/1000000是数据量,插入的都是string。第一个数据是最小时间,第二个是平均,第三个是数据大小。
db类型
最小时间
评价时间
数据大小
100000
dbmode
4.8
5.1
1477792
aofmode
9.1
9.3
3677803
300000
dbmode
16.5
17.6
4877792
aofmode
21.1
21.4
11477803
1000000
dbmode
61
65
16777792
aofmode
77
85
38777849
从简单分析来看,aof比rdb慢25-80%,但是大规模数据都比较支持慢25%这端。估计在低数据量下,rdb模式更加占优势。数据规模增长时,速率比接近于4:5。aof的数据比rdb数据大150%(2.5倍上下),这点随着数据增长基本不变。
从读性能分析来看,两者差异不大。同样,数据分别是最小时间和平均时间。
db类型
最小时间
评价时间
数据大小
dbmode
55
60
aofmode
62
63
差异在10%以内,甚至比最小-平均差异还弱。基本可以视为一致
Redis事务 Redis的乐观锁机制
大多数是基于数据版本(version)的记录机制实现的。即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个”version”字段来实现读取出数据时,将此版本号一同读出,之后更新时,对此版本号加1。此时,将提交数据的版本号与数据库表对应记录的当前版本号进行比对,如果提交的数据版本号大于数据库当前版本号,则予以更新,否则认为是过期数据。
Redis也采用类似的机制,使用watch命令会监视给定的key,当exec时候如果监视的key从调用watch后发生过变化,则整个事务会失败。也可以调用watch多次监视多个key。这样就可以对指定的key加乐观锁了。注意watch的key是对整个连接有效的,事务也一样。如果连接断开,监视和事务都会被自动清除。当然exec,discard,unwatch命令都会清除连接中的所有监视。
Redis锁概念
redis是单线程,提交命令时,其它命令无法插入其中,轻松利用单线程实现了事务的原子性。那如果执行多个redis命令呢?自然就没有事务保证,于是redis有下列相关的redis命令来实现事务管理。
命令
作用
multi
开启事务
exec
提交事务
discard
取消事务
watch
监控,如果监控的值发生变化,则提交事务时会失败
unwatch
去掉监控
Redis保证一个事务中的所有命令要么都执行,要么都不执行。如果在发送EXEC命令前客户端断线了,则Redis会清空事务队列,事务中的所有命令都不会执行。而一旦客户端发送了EXEC命令,所有的命令就都会被执行,即使此后客户端断线也没关系,因为Redis中已经记录了所有要执行的命令。
事务案例
例如:模拟转账,王有200,张有700,张给王转100。过程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 127.0 .0 .1 :6379 > set w 200 127.0 .0 .1 :6379 > set z 700 127.0 .0 .1 :6379 > mget w z1 ) "200" 2 ) "700" 127.0 .0 .1 :6379 > multi127.0 .0 .1 :6379 > decrby z 100 127.0 .0 .1 :6379 > incrby w 100 127.0 .0 .1 :6379 > mget w z127.0 .0 .1 :6379 > get w #同时,这些相关的变量也不能再读取127.0 .0 .1 :6379 > get z127.0 .0 .1 :6379 > exec1 ) (integer) 600 2 ) (integer) 300 3 ) 1 ) "300" 2 ) "600" 4 ) "300" 5 ) "600" 127.0 .0 .1 :6379 > mget w z1 ) "300" 2 ) "600" 127.0 .0 .1 :6379 >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 127.0 .0 .1 :6379 > mget w z1 ) "300" 2 ) "600" 127.0 .0 .1 :6379 > multi127.0 .0 .1 :6379 > get w127.0 .0 .1 :6379 > set w 100 127.0 .0 .1 :6379 > abc'abc' 127.0 .0 .1 :6379 > exec127.0 .0 .1 :6379 > mget w z #可以看出数据并未变化1 ) "300" 2 ) "600" 127.0 .0 .1 :6379 >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 127.0 .0 .1 :6379 > mget z w1 ) "600" 2 ) "300" 127.0 .0 .1 :6379 > multi127.0 .0 .1 :6379 > incrby z 100 127.0 .0 .1 :6379 > discard127.0 .0 .1 :6379 > get z"600" 127.0 .0 .1 :6379 > exec
1 2 3 4 5 6 7 8 9 10 11 12 13 14 127.0 .0 .1 :6379 > clear127.0 .0 .1 :6379 > set ticket 1 127.0 .0 .1 :6379 > set money 0 127.0 .0 .1 :6379 > watch ticket #乐观锁,对值进行观察,改变则事务失败127.0 .0 .1 :6379 > multi #开启事务127.0 .0 .1 :6379 > decr ticket127.0 .0 .1 :6379 > incrby money 100
1 2 3 4 5 127.0 .0 .1 :6379 > get ticket"1" 127.0 .0 .1 :6379 > decr ticket (integer) 0
1 2 3 4 5 6 127.0 .0 .1 :6379 > exec127.0 .0 .1 :6379 > get ticket"0" 127.0 .0 .1 :6379 > unwatch #取消监控
Redis海量数据导入
由于做性能测试,需要往redis中导出千万级的数据。得知redis-cli工具支持pipeline导入可以达到最佳性能。测试下500万条命令导入耗时43秒
将脚本写入文件用redis-cli --pipe导入
cat d.txt |redis-cli –pipe
格式要求
官方文档 数据格式要求
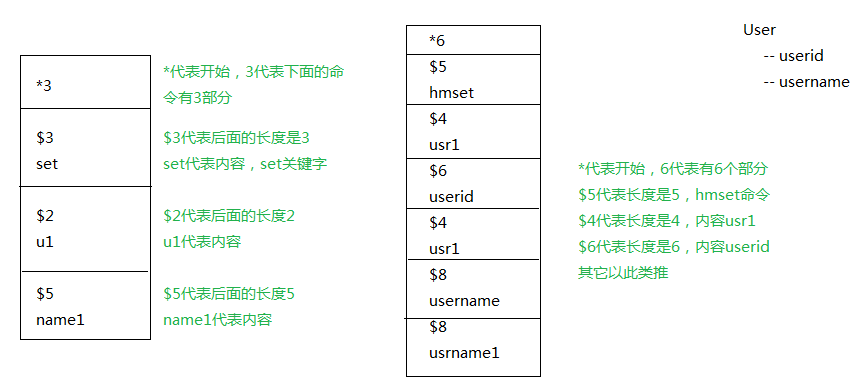
以*开始
*n n代表此条命令分成n个部分
每个部分以\r\n结束
案例
1 2 3 4 5 6 7 8 9 set name tony 表达为:3 \r\n3 \r\n4 \r\n4 \r\n
案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 package redis;import java.io.BufferedWriter;import java.io.FileOutputStream;import java.io.IOException;import java.io.OutputStreamWriter;import java.io.UnsupportedEncodingException;import org.junit.Test;public class TestRedisPipe {private String getString (String... args) {StringBuilder sb = new StringBuilder ();"*" ).append(args.length).append("\r\n" );for (String arg : args) {"$" ).append(arg.length()).append("\r\n" );"\r\n" );return sb.toString();@Test public void initFile2 () {Long startTime = System.currentTimeMillis();String file = "d:\\d.txt" ;BufferedWriter w = null ;StringBuilder sb = new StringBuilder ();try {new BufferedWriter (new OutputStreamWriter (new FileOutputStream (file), "utf-8" ));for (int i=100000000 ;i < 100100000 ;i++){if (i / 30000 == 0 ) {0 );this .getString("set" , "u" + i, "name" + i));catch (UnsupportedEncodingException e) {catch (Exception e) {finally {try {catch (IOException e) {long endTime = System.currentTimeMillis();"耗时: " +(endTime - startTime)/1000 +" s。" );
缓存预热
Redis启动两个服务 防火墙设置
1 2 [root@localhost ~]# systemctl stop firewalld #关闭防火墙@localhost ~]# systemctl disable firewalld #开机禁用
开启服务
参数:port端口,daemonize后台运行,protected-mode保护模式
1 2 redis-server --port 6379 --daemonize yes --protected -mode no6380 --daemonize yes --protected -mode no
Redis分片 获取redis客户端
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" "http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" >4.0 .0 </modelVersion>0.0 .1 -SNAPSHOT</version>2.9 .0 </version>1.6 .4 </version>
Jedis简单示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package redis;import java.util.List;import redis.clients.jedis.Jedis;public class TestRedis {public static void main (String[] args) {Jedis jedis = new Jedis ("192.168.115.115" ,6379 );"test1" ,"test2" );for (String s : oList){
使用连接池 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package cn.redis;import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisPool;import redis.clients.jedis.JedisPoolConfig;public class JedisPoolDemo {public static void main (String[] args) {JedisPoolConfig jedisPoolConfig = new JedisPoolConfig ();200 );JedisPool jedisPool = new JedisPool (jedisPoolConfig, " 192.168.163.101" , 6379 );Jedis jedis = jedisPool.getResource();"name" ));
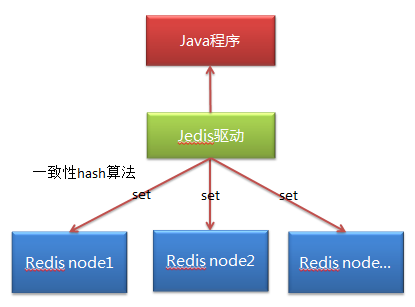
分片操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @Test public void shard () {new ArrayList <JedisShardInfo>();JedisShardInfo info1 = new JedisShardInfo ("192.168.163.200" ,6379 );JedisShardInfo info2 = new JedisShardInfo ("192.168.163.200" ,6380 );JedisShardInfo info3 = new JedisShardInfo ("192.168.163.200" ,6381 );JedisPoolConfig config = new JedisPoolConfig ();500 ); ShardedJedisPool pool = new ShardedJedisPool (config, infoList);ShardedJedis jedis = pool.getResource(); for (int i=0 ;i<10 ;i++){"n" +i, "t" +i);"n9" ));
分片原理
在分布式集群中,对机器的添加删除,或者机器故障后自动脱离集群这些操作是分布式集群管理最基本的功能。如果采用常用的hash(object)%N算法,那么在有机器添加或者删除后,很多原有的数据就无法找到了,这样严重的违反了单调性原则。(hash取余算法一般用在集合中)
Hash一致性算法
一致性哈希算法在1997年由麻省理工学院提出。
hash取余产生的问题:新增节点、删除节点会让绝大多数的缓存失效,除了导致性能骤降外很有可能会压垮后台服务器。
哈希一致性算法
解决对象:当集群中的节点新增或挂掉的时候,要对已有的节点的影响降到最小
解决方法:
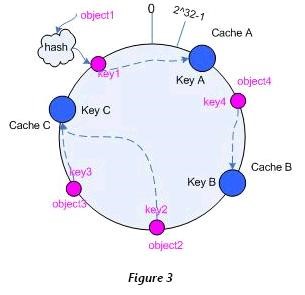
对缓存的object(key值)和Node(服务器节点值)使用同一个hash函数 (实际不需要完全一致,但至少保证产生的hash空间相同),让他们映射到同一个hash空间中去 ,当然这很容易实现,因为大多数的hash函数都是返回uint32类型,其空间即为1~232 232-1(2^32 = 4294 967 296,近43亿)**然后各个Node就将整个hash空间分割成多个interval空间,然后对于每个缓存对象object,都按照顺时针方向遇到的第一个Node负责缓存它。**通过这种方法,在新增加Node和删除Node的时候,只会对顺时针方向遇到的第一个Node负责的空间造成影响,其余的空间都仍然有效。
同时在以上基础上添加虚拟Node的实现 ,即Node-1会有多个分身Node-1-1,Node-1-2等虚拟节点来替自身回收散布在Hash环上的值。通过这种方法,在添加删除Redis服务器或初始Hash计算Node值位置不平均时,保证object仍然能平均被分配给对应的Node服务器
注意:虽然虚拟并不能百分百的解决缓存命中失效的问题,但把问题缩小化,这样影响面小,即使缓存失效,数据库也能承受起用户的负载,从而稳定过渡。
Hash一致性的特征 单调性(Monotonicity) 单调性是指如果已经有一些请求通过哈希分派到了相应的服务器进行处理,又有新的服务器加入到系统中时候,应保证原有的请求可以被映射到原有的或者新的服务器中去,而不会被映射到原来的其它服务器上去。
分散性(Spread) 分布式环境中,客户端请求时候可能不知道所有服务器的存在,可能只知道其中一部分服务器,在客户端看来他看到的部分服务器会形成一个完整的hash环。如果多个客户端都把部分服务器作为一个完整hash环,那么可能会导致,同一个用户的请求被路由到不同的服务器进行处理。这种情况显然是应该避免的,因为它不能保证同一个用户的请求落到同一个服务器。所谓分散性是指上述情况发生的严重程度。好的哈希算法应尽量避免尽量降低分散性。
平衡性(Balance) 平衡性也就是说负载均衡,是指客户端hash后的请求应该能够分散到不同的服务器上去。一致性hash可以做到每个服务器都进行处理请求,但是不能保证每个服务器处理的请求的数量大致相同。
负载(Load) 负载问题实际上是从另一个角度看待分散性 问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。