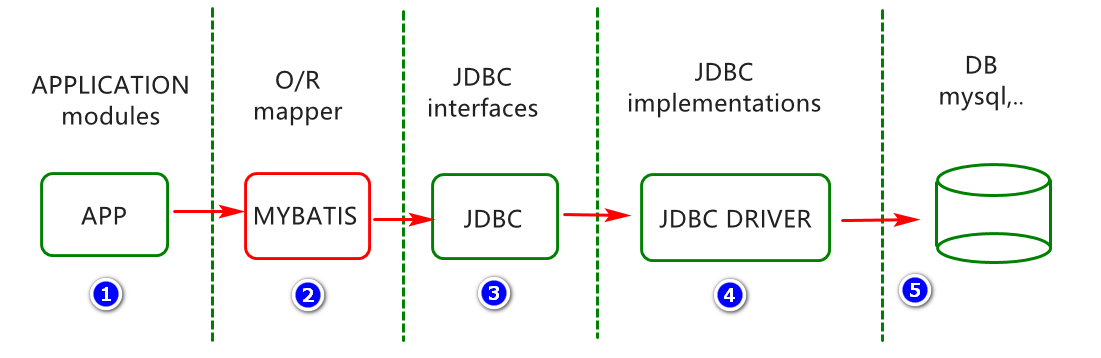
架构分析 应用架构分析 Mybatis 是一个优秀的持久层框架,底层基于 JDBC 实现与数据库的交互,并在
Mybatis 之所以能够成为互联网项目中持久层应用的翘楚,其核心竞争力应该是它灵活的 SQL 定制,参数及结果集的映射。
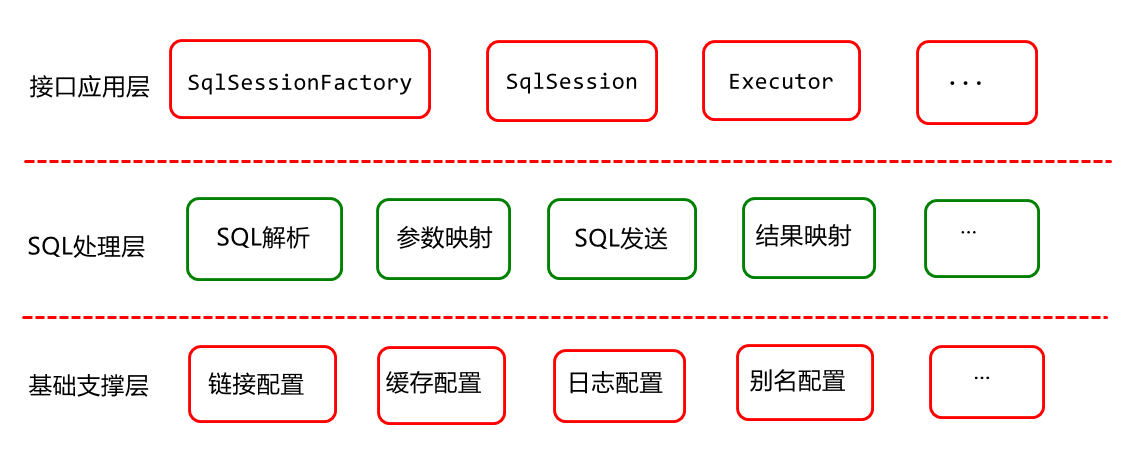
产品架构分析 互联网项目中的任何一个框架都可以看成是一个产品,每个产品都有它自己的产品架构,Mybatis 也不例外,它的产品架构主要可以从接口应用,SQL
所有想成为平台架构师的程序员,在应用一个互联网框架的过程中都应对框架的设计理念,实现思路有一个很好的认知,并基于认知强化实践过程,拓展产品架构思维。
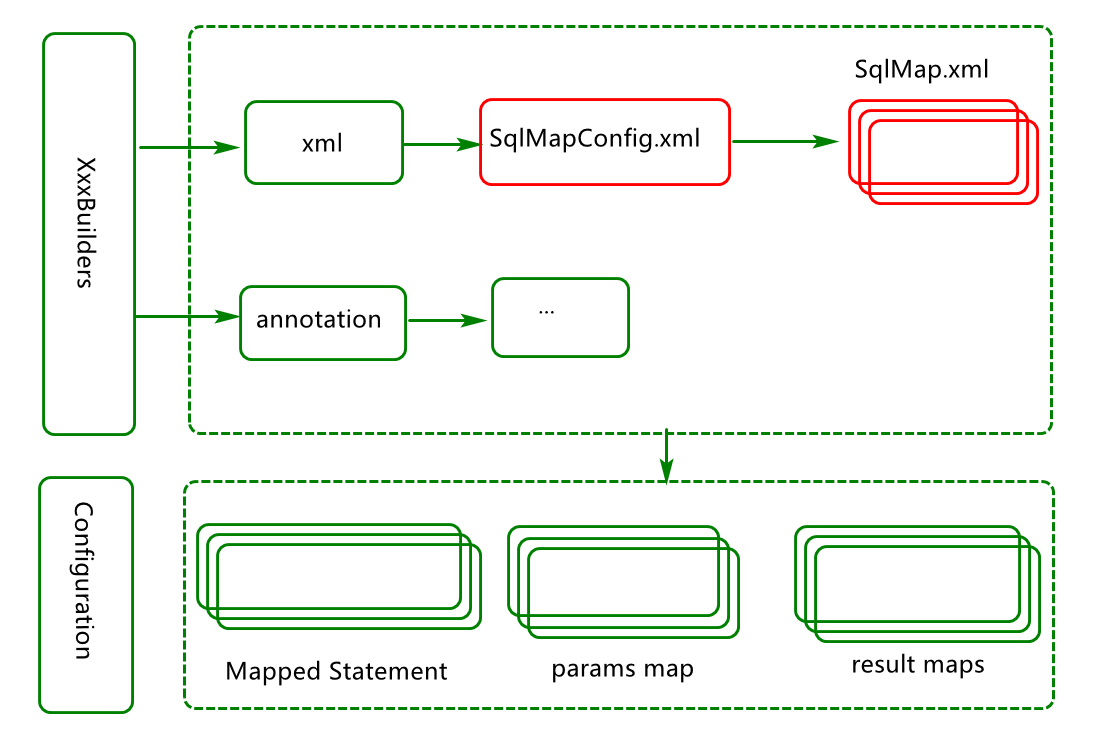
技术架构分析 mybatis配置的核心均是通过读取配置xml文件或注解annotation来实现配置的加载。这些配置均会放在各种集合中(如下图所示),而这些集合将会被configuration 类综合管理
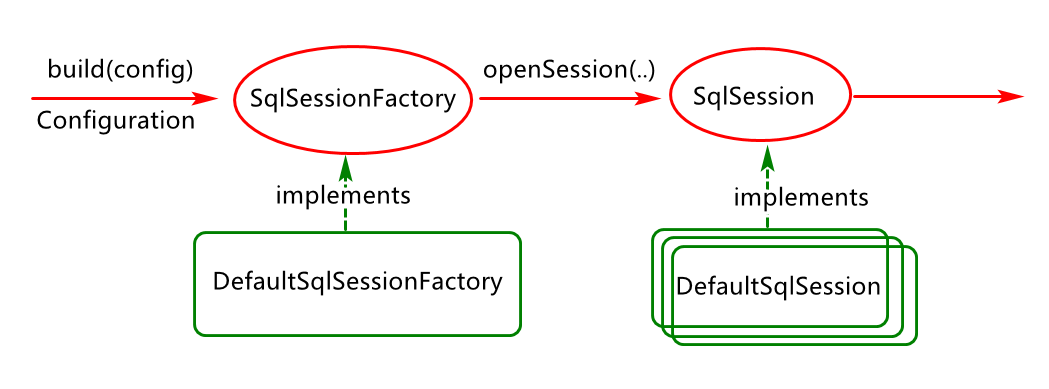
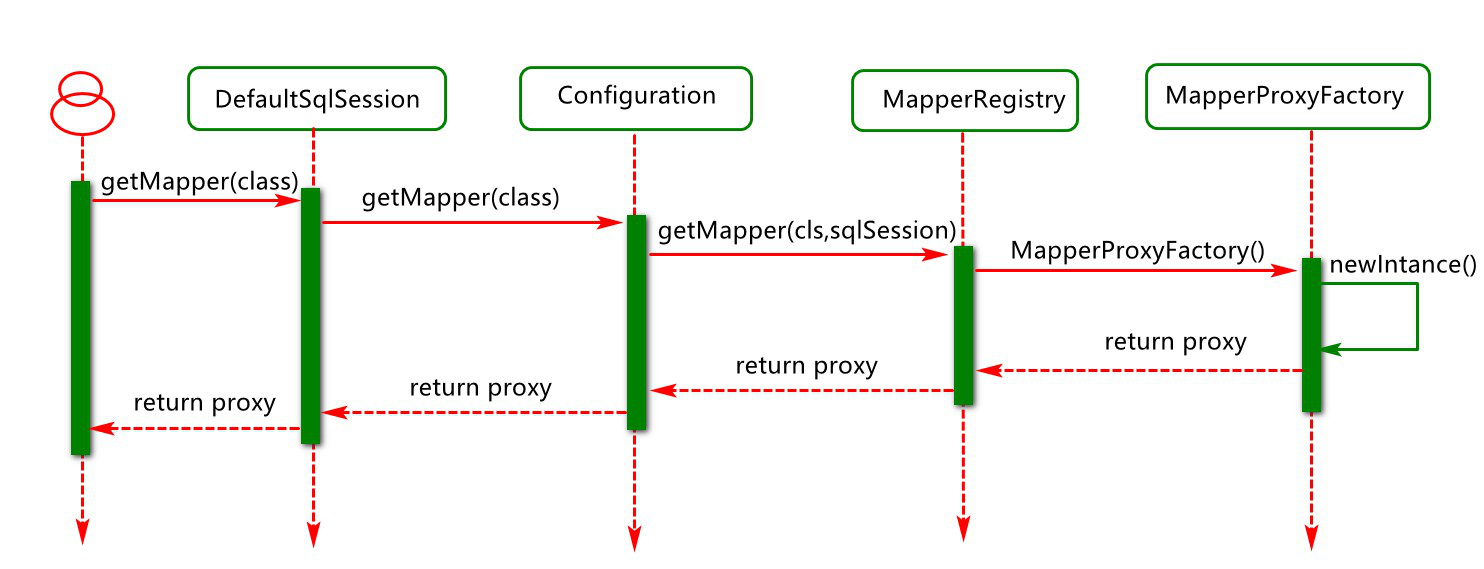
mybatis会暴露一个API主要为用户操作的API,SqlSession通过SqlSessionFactoryBactory工厂创建来执行sql操作
Mybatis实践 SqlSessionFactory
SqlSessionFactory 工厂对象创建分析
系统底层会通过流读取所有mybatis配置以及mapper文件
这些数据存储到对应的对象或集合中,几乎所有的数据均由configuration对象管理
上述操作均是通过构造者XmlConfigBuilder和一系列构造者 实现,并将数据存储到configuration中
1 2 3 4 5 6 7 8 9 10 11 12 13 @Before public void init () throws IOException{"mybatis-configs.xml" );new SqlSessionFactoryBuilder ().build(in);
SqlSessionFactory 创建之时序图分析
XmlConfigBuilder分析 XmlConfigBuilder中主要做了两种操作
读取流(读取为document对象)
赋值configuration
流的读取位于xmlConfigBuilder的构造方法中,其主要职责就是已document的方式读出流,这里后续不做具体分析;
后续会进行数据封装,参考封装
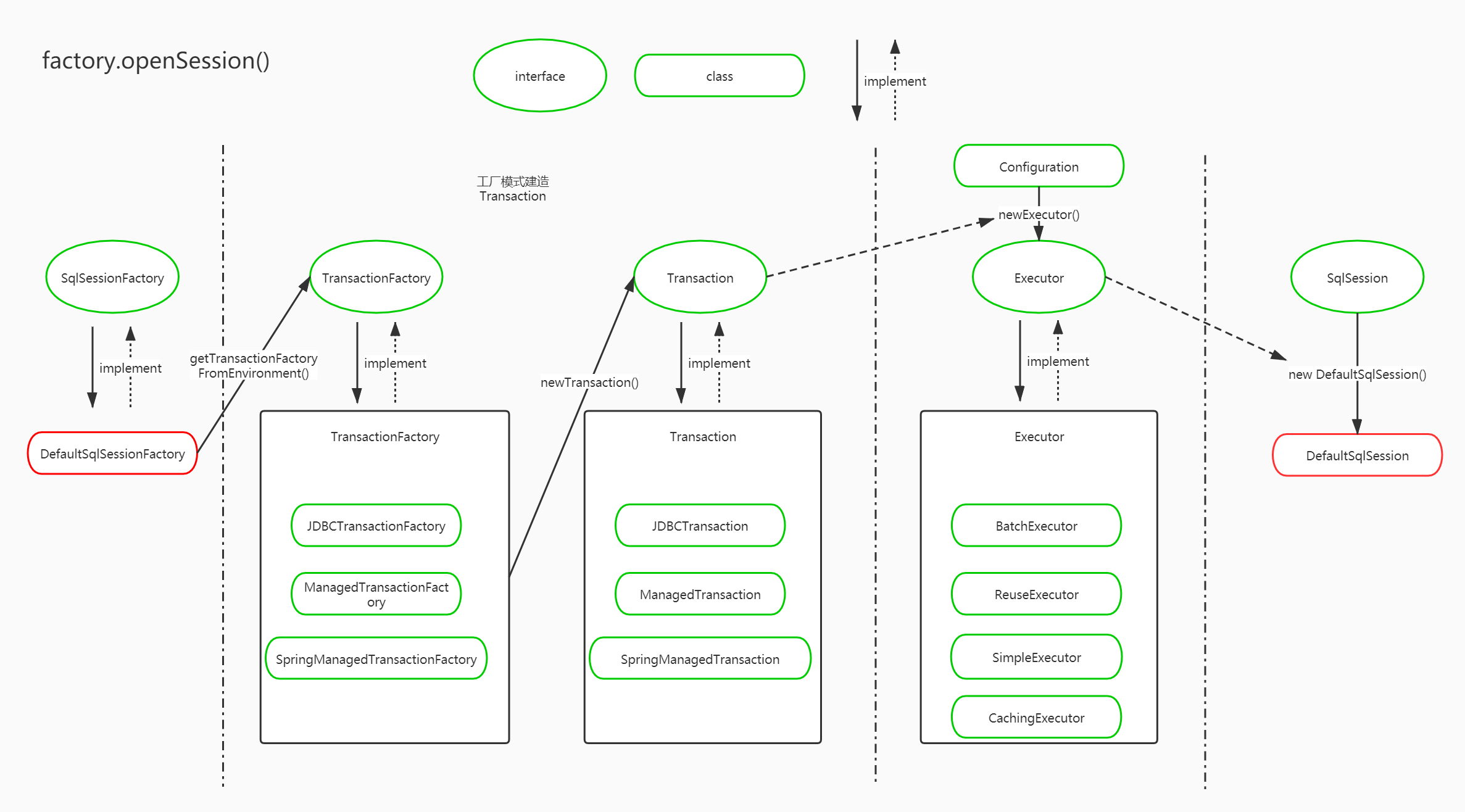
OpenSession
SqlSession对象生成分析
获取数据源,生成TransactionFactory(数据源在加载配置的时候就已经初始化)
初始化需要的Executor
SqlSession
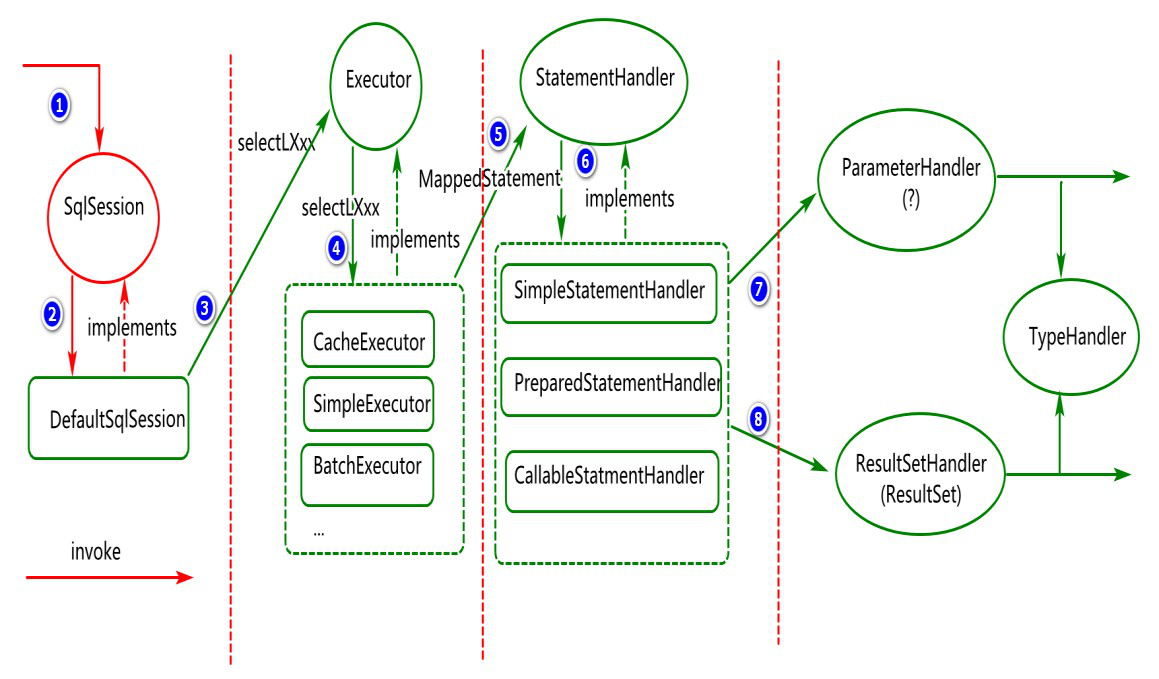
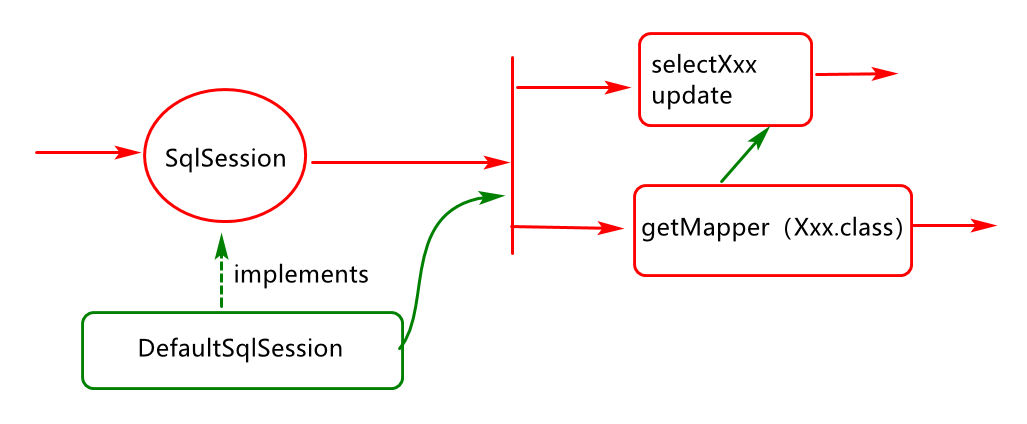
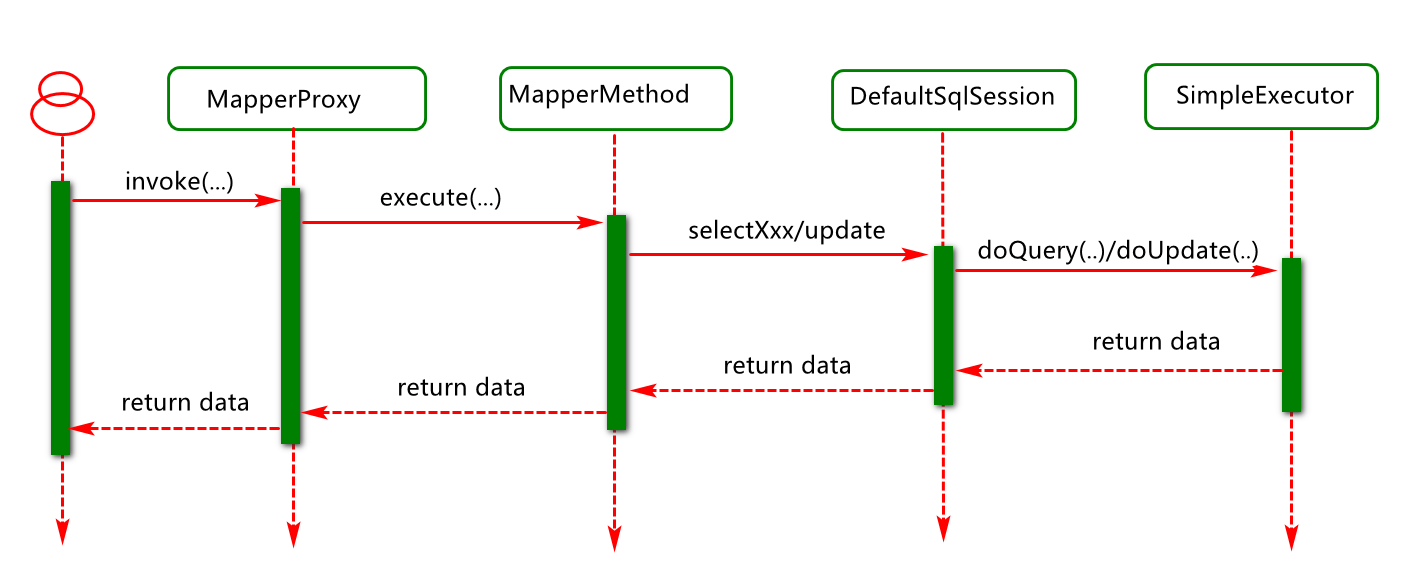
SqlSession 对象应用过程分析
SqlSession默认都是使用defaultSqlSession
SqlSession会通过Configuration对象获取存储的MappedStatement,即mapper文件写的sql
SqlSession是通过配置文件命名空间+sql的ID来匹配对应map的key查询MappedStatement
MapperStatememt保存对应mapper文件指定的sql及相关sql配置
SqlSession通过内部的Executor执行器去执行sql的查询(当开启缓存是会优先执行CachedExecutor)
BaseExecutor是mybatis的默认缓存执行器,它是一个装饰者装饰其它默认执行器,因此当其它执行器执行时均会执行它
最终通过封装过的StatementHandler来执行sql(statement)类似JDBC,参考JDBC
mapper
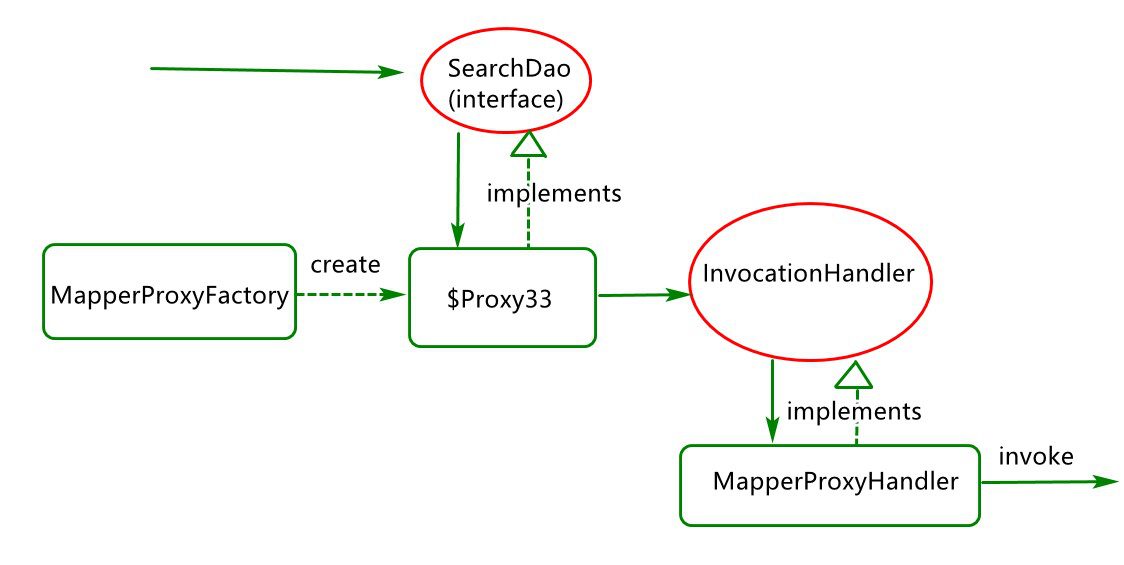
Mapper接口对象应用方式分析
mybatis会通过mapper接口对象的路径和方法获取到statement的key值以便获取到MapperStatement
它是由JDK动态代理来实现的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 import java.lang.reflect.InvocationHandler;import java.lang.reflect.Method;import java.lang.reflect.Proxy;import java.util.List;public class ProxyFactory {this .dao = dao;newInstance (InvocationHandler handler) {return Proxy.newProxyInstance(dao.getClassLoader(),new Class <?>[]{dao},handler);interface MybatisDao {selectAll () ;class MybatisProxyHandler implements InvocationHandler {this .sqlSession = sqlSession;this .daoInterface = daoInterface;@Override public Object invoke (Object proxy, Method method, Object[] args) throws Throwable {"invocation handler" );String className = daoInterface.getName();String methodName = method.getName();String statement = className+methodName;return null ;interface SqlSession {query (String statement) ;class DefaultSqlSession implements SqlSession {@Override public Object query (String statement) {"query data from statement:" +statement);return null ;class test {public static void main (String[] args) {SqlSession sqlSession = new DefaultSqlSession ();InvocationHandler invocationHandler = new MybatisProxyHandler (sqlSession,daoInterfase);ProxyFactory factory = new ProxyFactory (daoInterfase);MybatisDao proxy = (MybatisDao)factory.newInstance(invocationHandler);
Mapper 代理对象数据访问应用过程分析
可见基于接口实现mybatis的sql调度也是通过基础的session.selectList(statement);操作来实现的
生命周期 正确的使用mybatisAPI需要事先了解各个API对象的生命周期,以便我们知道他们之间的地位关系,错误的使用会导致非常严重的并发问题。
提示:依赖注入框架可以创建线程安全的、基于事务的 SqlSession 和映射器,并将它们直接注入到你的 bean 中,因此可以直接忽略它们的生命周期。可以研究一下 MyBatis-Spring 或 MyBatis-Guice 两个子项目 。
SqlSessionFactoryBuilder :这个类可以被实例化、使用和丢弃,一旦创建了 SqlSessionFactory,就不再需要它了。 因此
其它对象应用分析 数据封装及初始化分析 mapper加载分析 XmlConfigBuilder
内部的parseConfiguration 方法可以清晰的找到所有数据的封装方法,以mapper为例
XMLMapperBuilder
我们都知道mybatis_config主配置文件中的mappers存储的是所有mapper文件的路径,myubatis基于这个路径找到具体的每个mapper文件
mapper文件的读取和封装类似mybatis的主配置文件,都是由builder类的构造方法负责读取流,parse()这里可以看到框架重新启用了一个构造者XMLMapperBuilder去封装数据。
进入parse()方法可以看到它会从mapper配置文件的根目录标签“mapper”开始解析。
通过isResourceLoaded(),addLoadedResource()方法实现配置文件的缓存
后续parsePendingResultMaps(),parsePendingCacheRefs(),parsePendingStatements()方法负责重新加载初始化配置数据,即二次加载,这里不做详细描述
mapper配置文件封装操作在configurationElement()方法
如下图所示,可以看到是对mapper下的各种属性的封装和初始化,包括命名空间,结果集,参数集等
sql语句封装具体在buildStatementFromContext()方法
XMLStatementBuilder 逐步进入方法,(其中会有包含mybatis多数据库支持的逻辑方法,在以后的章节中会聊)最终找到XMLStatementBuilder,这个构造者用于封装具体select|insert|update|delete标签中的属性和语句
可以清晰的看见它通过parseStatementNode()方法完成数据封装
最终可以找到它会用到MapperBuilderAssistant类来辅助封装数据
MapperBuilderAssistant在初始化XMLMapperBuilder对象时的构造函数中初始化,即一个mapper文件对应一个builderAssistant
方法中会用到langDriver.createSqlSource(configuration, context, parameterTypeClass);
利用applyCurrentNamespace()方法生产key,该key将作为以后查询这个sql的索引
addMappedStatement()方法最终具体实现了sql 数据封装,即将SqlSource等类型数据加入主配置Configuration中
MapperStatment.Builder
在封装方法中可以找到新启动了一个MappereStatment
最后通过configuration的addMappedStatement()
总结 XmlConfigBuilder 作为总构造者,负责加载调度其它构造者参与进程。其中XmlMapperBuilder XmlStatementBuilder 是mapperBuilder下主要用来封装<insert/>|<update/>|<delete/>|<select/>
builder包含关系如下:
Sql标签及多数据库支持 当我们在MapperConfiguration配置文件中添加如下配置时,默认开启多数据库支持;此时,mybatis会根据当前链接的数据库来为Configuration配置匹配正确的数据库配置(
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 mybatis-config.xml<databaseIdProvider type ="DB_VENDOR" > <property name ="Oracle" value ="oracle" /> <property name ="MySQL" value ="mysql" /> </databaseIdProvider > <sql id ="selectAll" databaseId ="mysql" > </sql > <select id ="selectStudentsBySQLFragment" resultType ="org.example.pojo.Student" > <include refid ="selectAll" > </include > <if test ="list != null and list.size > 0" > <foreach collection ="list" open ="(" close =")" separator ="," item ="item" > </foreach > </if > </select >
多数据库配置识别封装 该方法位于XMLConfigBuilder.java这个构建者中,核心方法是最后两行
databaseIdProvider.getDatabaseId(environment.getDataSource());:可以看出它会获取数据源,随后在方法中执行以下两个操作:
从数据源中获取数据源名称,此例中即:”MySQL”
匹配上文的</databaseIdProvider>标签内的配置,当能匹配上时则进行辅助;相反,没有匹配则不作配置;
configuration.setDatabaseId(databaseId);进行配置
多数据库配置使用 下文中会分别解析Sql标签的实现原理以及databaseId实现多数据配置的使用原理
在上文的xml文件的Mapper配置中,以<sql/>标签为例,它的databaseId为“mysql”
在构建者XMLMapperBuilder中,找到Sql的封装方法,这里不做截图:
sqlElement(context.evalNodes("/mapper/sql"));
进入有databaseId配置的方法,注意:这里获取的databaseId是先前从主配置文件中封装的
该方法有以下几步
获取属性值,
id:用于生成key值id,将来座位索引
databaseId:会用于匹配先前在主配置文件中配置并加载的databaseId
生成ID:这个ID会成为索引key来方便以后进行调用
判断匹配两个databaseID是否一样,若一样则进行存储
总结:
多数据库配置指的是当mybatis连接特定数据库时,只读取与这个数据库相关的sql(前提是我们要配置databaseId);它的配置存储在Configuration主配置类的databaseId变量中;程序读取mapper文件后会一一获取它们的databaseId属性来逐一判断是否加载;
关于sql标签的调用 上文用到sql标签的存储来演示多数据库配置,那sql标签是如何被调用的呢?
上文中提到sql标签中的内容会被存到一个sqlFragments的集合中,这个集合虽然是XmlMapperBuilder构建者的成员变量,但是它的初始化实际上是在Configuration主配置中实现的。因此可得出,在特定配置文件配置的sqlNode是可以全局使用它的,但是sql标签的加载必须先于include标签的加载 ;
调用位于具体的<select/><insert/><delete/><update/>标签加载方法中,在SqlSource对象生成之前;(SqlSource对象是实现动态sql,数据拼接的基础;
该方法之前有分析过,可参考XMLStatementBuilder
内部实现
该方法运用递归的方式逐一查找每个子节点,找到那些需要替换的include标签进行替换
同时当有符合${}表达式的参数时执行注入(注意:该操作只作用于sql标签中OGNL表达式)
动态Mappere分析 sql封装结构 树和mapper文件对应关系 mybatis需要在用户内存空间中暂存sql数据,以便后续及时调用,而存在内存空间的结构需要仰仗mybatis的Sql数据结构
mybatis中sql的数据结构是mybatis框架的重要组成部分,实现动态sql,sql参数传递等操作均要依赖于优秀的数据结构,下面将介绍mybatis框架实现在这种数据结构的方案
mybatis的sql数据结构基于组合模式 实现,这种模式将对象组合成树形结构以表示“部分-整体”的层次结构,而在mybatis的sql数据封装中,会将每个<insert/>|<update/>|<delete/>|<select/>标签中的sql内容封装到这种树型结构中(即:每条sql为一棵树结构),如下图所示。
这些树最终将封装到MappereStatment封装 对象中,受Configuration对象的MappedStatements集合管理。
树的实现
标准的组合模式分为三个结构
Component :组合中的对象声明接口,在适当的情况下,实现所有类共有接口的默认行为。声明一个接口用于访问和管理Component子部件。
Leaf:叶子对象。叶子结点没有子结点。
Composite:容器对象,定义有枝节点行为,用来存储子部件,在Component接口中实现与子部件有关操作,如增加(add)和删除(
在mybatis中,上述组合部件对应的类如下
Component 作为整个树的接口,由SqlNode实现,它下面有一个公共方法apply()
Leaf子叶对象则会有很多种,它们各有各自的作为,在mapper文件中对应<insert/>|<update/>|<delete/>|<select/>apply()方法,常见的类包括:TextSqlNode、IfSqlNode、StaticTextSqlNode等。
Composite容器对象由MixedSqlNode实现,同样也继承自SqlNode接口,实现自定义的apply()方法。容器用于承载各种Leaf子叶对象
此外DynamicContext对象作为apply()方法的参数,作用是封装具体的sql操作,如sql的获取和拼接等
容器MixedSqlNode 1 2 3 4 5 6 7 8 9 10 11 public class MixedSqlNode implements SqlNode {private final List<SqlNode> contents;public MixedSqlNode (List<SqlNode> contents) {this .contents = contents;public boolean apply (DynamicContext context) {...}
子叶StaticTextSqlNode 用于封装静态sql语句,mybatis会识别sql语句是否有${}符号,若没有动态sql符号则新建StaticTextSqlNode对象存储这条sql
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class StaticTextSqlNode implements SqlNode {private final String text;public StaticTextSqlNode (String text) {this .text = text;@Override public boolean apply (DynamicContext context) {this .text);return true ;
子叶TextSqlNode 用于封装动态sql语句,与StaticTextSqlNode相反,当有${}符号时自动封装语句到该对象
内部会用到两个内部类来辅助完成sql拼接和动态sql判断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class TextSqlNode implements SqlNode {private final String text;private final Pattern injectionFilter;public TextSqlNode (String text) {this (text, null );public TextSqlNode (String text, Pattern injectionFilter) {this .text = text;this .injectionFilter = injectionFilter;public boolean isDynamic () {...}public boolean apply (DynamicContext context) {...}private static class BindingTokenParser implements TokenHandler {...}private static class DynamicCheckerTokenParser implements TokenHandler {...}
动态sql标签 子叶节点sql中,均是以xml节点形式存在,这种节点会利用ognl类库来辅助完成实现test属性的解析
子叶标签IfSqlNode
节点SqlNode中会多出一个表达式解析器用于解析和判断节点中test属性对应的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class IfSqlNode implements SqlNode {private final ExpressionEvaluator evaluator;private final String test;private final SqlNode contents;public IfSqlNode (SqlNode contents, String test) {this .test = test;this .contents = contents;this .evaluator = new ExpressionEvaluator ();public boolean apply (DynamicContext context) {if (evaluator.evaluateBoolean(test, context.getBindings())) {return true ;return false ;
下面会给出案例,两个if节点会封装成如下形式
1 2 3 4 5 6 7 8 9 10 <select id ="selectStudentsIf" resultType ="org.example.pojo.Student" > <if test ="name != null and name != ''" > </if > <if test ="age > 0" > </if > </select >
1 2 3 4 5 6 7 8 9 10 11 12 13 MixedSqlNode: [ : "select * from student where 1=1" , : test: "name != null and name != ''" : content[ : "and name like '%' #{name} '%'" ] , : test: "age > 0" : content[ : "and name like '%' #{name} '%'" ] ] ]
子叶标签TrimSqlNode 案例 要知道TrimSqlNode首先需要了解<trim/>标签的作用,trim标记是一个格式化的标记,可以完成set或者是where标记的功能
详情可参考如下案例
1 2 3 4 5 6 7 8 9 10 11 12 13 select * from user<trim prefix ="WHERE" prefixoverride ="AND |OR" > <if test ="name != null and name.length()>0" > AND name=#{name}</if > <if test ="gender != null and gender.length()>0" > AND gender=#{gender}</if > </trim >
假如说name和gender的值都不为null的话打印的SQL为:select * from user where and name = ‘xx’ and gender = ‘xx’
在删除线标记的地方是不存在第一个and的,上面两个属性的意思如下:
prefix:前缀+ prefixoverride:去掉第一个and或者是or
1 2 3 4 5 6 7 8 9 10 11 12 13 update user<trim prefix ="set" suffixoverride ="," suffix =" where id = #{id} " > <if test ="name != null and name.length()>0" > name=#{name} ,</if > <if test ="gender != null and gender.length()>0" > gender=#{gender} ,</if > </trim >
假如说name和gender的值都不为null的话打印的SQL为:update user set name=’xx’ , gender=’xx’ , where id=’x’
在删除线标记的地方不存在逗号,而且自动加了一个set前缀和where后缀,上面三个属性的意义如下,其中prefix意义如上:
suffixoverride:去掉最后一个逗号(也可以是其他的标记,就像是上面前缀中的and一样)
suffix:后缀
原文链接
原理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class TrimSqlNode implements SqlNode {private final SqlNode contents;private final String prefix;private final String suffix;private final List<String> prefixesToOverride;private final List<String> suffixesToOverride;private final Configuration configuration;public boolean apply (DynamicContext context) {FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext (context);boolean result = contents.apply(filteredDynamicContext);return result;private class FilteredDynamicContext extends DynamicContext {public void applyAll () {new StringBuilder (sqlBuffer.toString().trim());String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);if (trimmedUppercaseSql.length() > 0 ) {
子叶标签WhereSqlNode WhereSqlNode实际上是基于trim实现,因此WhereSqlNode继承TrimSqlNode共享它的所有方法,不同之处在于自动为TrimSqlNode添加了需要的初始化属性。
1 2 3 4 5 6 7 8 9 public class WhereSqlNode extends TrimSqlNode {private static List<String> prefixList = Arrays.asList("AND " ,"OR " ,"AND\n" , "OR\n" , "AND\r" , "OR\r" , "AND\t" , "OR\t" );public WhereSqlNode (Configuration configuration, SqlNode contents) {super (configuration, contents, "WHERE" , prefixList, null , null );
子叶节点SetSqlNode 原理同上
1 2 3 4 5 6 7 8 9 public class SetSqlNode extends TrimSqlNode {private static List<String> suffixList = Arrays.asList("," );public SetSqlNode (Configuration configuration,SqlNode contents) {super (configuration, contents, "SET" , null , null , suffixList);
子叶节点ForEachSqlNode 案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <select id ="selectStudentsForeachArray" resultType ="org.example.pojo.Student" > <if test ="array != null and array.length > 0" > <foreach collection ="array" open ="(" close =")" separator ="," item ="item" > </foreach > </if > </select > <select id ="selectStudentsForeachList2" resultType ="org.example.pojo.Student" > <if test ="list != null and list.size > 0" > <foreach collection ="list" open ="(" close =")" separator ="," item ="item" > </foreach > </if > </select >
原理 说明样例:<foreach collection="list" open="(" close=")" separator="," item="item">
open,close,参数为简单的参数拼接
collection会利用ognl类库来实现参数的获取,array标识获取数组类型,list标识获取集合类型
separator会通过装饰着PrefixedContext来扩展实现DynamicContext的功能,来逐步为后续sqlNode拼接上述样例中的“,”
由于参数集是以map集合来实现的,item会用于设定索引,来存储遍历出的每个对象;儿后续子叶sqlNode中会通过DynamicContext获取到这个map并从中获取value值来拼接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 public class ForEachSqlNode implements SqlNode {public static final String ITEM_PREFIX = "__frch_" ;private final ExpressionEvaluator evaluator;private final String collectionExpression;private final SqlNode contents;private final String open;private final String close;private final String separator;private final String item;private final String index;private final Configuration configuration;@Override public boolean apply (DynamicContext context) {final Iterable<?> iterable = evaluator.evaluateIterable(collectionExpression, bindings);if (!iterable.iterator().hasNext()) {return true ;boolean first = true ;int i = 0 ;for (Object o : iterable) {DynamicContext oldContext = context;if (first || separator == null ) {new PrefixedContext (context, "" );else {new PrefixedContext (context, separator);int uniqueNumber = context.getUniqueNumber();if (o instanceof Map.Entry) {@SuppressWarnings("unchecked") else {new FilteredDynamicContext (configuration, context, index, item, uniqueNumber));if (first) {return true ;private class PrefixedContext extends DynamicContext {...}
剩下的标签还有ChooseSqlNode,WhenSqlNode,OtherWiseSqlNode等,他们的原理与之前将的几个SqlNode相差无几,后面不多赘述;
SqlNode组合构成实现 启动类的初始化
mybatis的sqlNode构成实现启动类为XMLScriptBuilder,XMLScriptBuilder在初始化时会分别为context(解析xml中的sql)
启动类启动
parseScriptNode()方法是在初始化后被直接调用,也是启动类的启动方法,具体可查看XMLLanguageDriver类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public SqlSource parseScriptNode () {MixedSqlNode rootSqlNode = this .parseDynamicTags(this .context);SqlSource sqlSource = null ;if (this .isDynamic) {new DynamicSqlSource (this .configuration, rootSqlNode);else {new RawSqlSource (this .configuration, rootSqlNode, this .parameterType);return (SqlSource)sqlSource;
封装SqlNode
启动方法的主要逻辑实现在parseDynamicTags()方法,如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 protected MixedSqlNode parseDynamicTags (XNode node) {new ArrayList <SqlNode>();NodeList children = node.getNode().getChildNodes();for (int i = 0 ; i < children.getLength(); i++) {XNode child = node.newXNode(children.item(i));if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {String data = child.getStringBody("" );TextSqlNode textSqlNode = new TextSqlNode (data);if (textSqlNode.isDynamic()) {true ;else {new StaticTextSqlNode (data));else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { String nodeName = child.getNode().getNodeName();NodeHandler handler = nodeHandlerMap.get(nodeName);if (handler == null ) {throw new BuilderException ("Unknown element <" + nodeName + "> in SQL statement." );true ;return new MixedSqlNode (contents);
不同handler会有特有的自定义封装初始化以及特定的handleNode(child, contents)方法的操作,但大体流程一致
再次调用parseDynamicTags()方法封装这个子节点child内部子节点,递归的方式;并返回一个容器即MixedSqlNode,这个容器则是这个树状分支的分支即组合模式的component
解析Node标签中的属性如test等
新建特定的SqlNode(不同Handler处理不同的SqlNode)将获取的component分支以及Node标签属性传入它们的构造函数
将这个封装好的子叶SqlNode加入contents
DynamicContext类 DynamicContext用于封装请求参数,即我们查询数据库的实体类或基本数据类型等,该参数会以Object类型以DefaultSqlSession->
而它最终应用于先前的各种SqlNode的apply方法中,以达到各种参数的获取,表达式的实现等;
下面对DynamicContext进行解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 public class DynamicContext {public static final String PARAMETER_OBJECT_KEY = "_parameter" ;public static final String DATABASE_ID_KEY = "_databaseId" ;static {new ContextAccessor ());private final ContextMap bindings;private final StringBuilder sqlBuilder = new StringBuilder ();private int uniqueNumber = 0 ;public DynamicContext (Configuration configuration, Object parameterObject) {if (parameterObject != null && !(parameterObject instanceof Map)) {MetaObject metaObject = configuration.newMetaObject(parameterObject);new ContextMap (metaObject);else {new ContextMap (null );static class ContextMap extends HashMap <String, Object> {private MetaObject parameterMetaObject;public ContextMap (MetaObject parameterMetaObject) {this .parameterMetaObject = parameterMetaObject;@Override public Object get (Object key) {String strKey = (String) key;if (super .containsKey(strKey)) {return super .get(strKey);if (parameterMetaObject != null ) {return parameterMetaObject.getValue(strKey);return null ;static class ContextAccessor implements PropertyAccessor {@Override public Object getProperty (Map context, Object target, Object name) throws OgnlException {Map map = (Map) target;Object result = map.get(name);if (map.containsKey(name) || result != null ) {return result;Object parameterObject = map.get(PARAMETER_OBJECT_KEY);if (parameterObject instanceof Map) {return ((Map)parameterObject).get(name);return null ;
使用流程:
在映射参数之前,程序会初始化DynamicContext,并在构造函数中,为其成员ContextMap注入MetaObject;MetaObject封装请求参数param对象相关的反射信息
程序通过组合模式的树状结构,逐层向下调用apply方法,并传入DynamicContext
当有SqlNode需要映射#{}符号中的参数时,会调用对应的TokenParser方法从Ognl表达式中取值;
由于我们先前注册过ContextAccessor存取器,因此会Ognl表达式会优先通过存取器从ContextMap取值
最后通过DynamicContext的appendSql方法来拼接对应的#{}符号(这个符号会在特定方法中别替换,具体看GenericTokenParser.parse(
此外DynamicContext也是实现动态sql的核心,实际上拼接映射参数和动态同时进行,例如TextSqlNode负责拼接#{}参数,而ifSqlNode负责动态sql根据不同的sqlNode实现不同的功能;
Sql封装 Sql封装分为两部分,分别为表达式封装,参数封装,以及Sql封装
表达式封装,参考下一节“表达式#{}操作”
Sql封装,参考上一节“动态Mapper分析”以及”DynamicContext类“
封装容器为SqlSource
SqlSource最终返回BoundSql,而里面的成员数据也均赋值于BoundSql,BoundSql参与后续的Sql语句执行
SqlSource分析 实际上在XMLStatementBuilder篇章就讲了SqlSource的部分功能,它用于封装已成树状结构的SqlNode;
SqlSource分为三种DynamicSqlSource,RawSqlSource,StaticSqlSource,下面逐一分析
*SqlSource有两个主要成员,初始化构造函数,和getBoundSql()方法
以上三种sqlSource的初始化即是封装 ,封装过程在mapper配置加载阶段
getBoundSql()方法在执行sql操作时被调用
DynamicSqlSource 顾名思义,当xml中的sql语句为动态sql时,默认用DynamicSqlSource封装数据,(sql中有${}也用该方案封装)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class DynamicSqlSource implements SqlSource {private final Configuration configuration;private final SqlNode rootSqlNode;public DynamicSqlSource (Configuration configuration, SqlNode rootSqlNode) {this .configuration = configuration;this .rootSqlNode = rootSqlNode;@Override public BoundSql getBoundSql (Object parameterObject) {DynamicContext context = new DynamicContext (configuration, parameterObject);SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder (configuration);null ? Object.class : parameterObject.getClass();SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());BoundSql boundSql = sqlSource.getBoundSql(parameterObject);return boundSql;
RawSqlSource 当mapper文件里的sql语句时文本时则使用RawSqlSource
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class RawSqlSource implements SqlSource {private final SqlSource sqlSource;public RawSqlSource (Configuration configuration, SqlNode rootSqlNode, Class<?> parameterType) {this (configuration, getSql(configuration, rootSqlNode), parameterType);public RawSqlSource (Configuration configuration, String sql, Class<?> parameterType) {SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder (configuration);null ? Object.class : parameterType;new HashMap <>());private static String getSql (Configuration configuration, SqlNode rootSqlNode) {DynamicContext context = new DynamicContext (configuration, null );return context.getSql();@Override public BoundSql getBoundSql (Object parameterObject) {return sqlSource.getBoundSql(parameterObject);
StaticSqlSource 已完成封装的sqlSource,以上两种最终都会封装到staticSqlSource中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class StaticSqlSource implements SqlSource {private final String sql;private final List<ParameterMapping> parameterMappings;private final Configuration configuration;public StaticSqlSource (Configuration configuration, String sql) {this (configuration, sql, null );public StaticSqlSource (Configuration configuration, String sql, List<ParameterMapping> parameterMappings) {this .sql = sql;this .parameterMappings = parameterMappings;this .configuration = configuration;@Override public BoundSql getBoundSql (Object parameterObject) {return new BoundSql (configuration, sql, parameterMappings, parameterObject);
总结
无论是DynamicSqlSource还是RawSqlSource,最终都会转化为StaticSqlSource执行getBoundSql方法获取boundSql;
DynamicSqlSource和RawSqlSource差异
DynamicSqlSource动态sql部分在请求数据库时执行,而RawSqlSource的动态sql部分在mybatis组件加载时执行,因此DynamicSqlSource有性能损失
表达式#{}操作
表达式封装位于SqlSourceBuilder类中,它会在Executor执行器执行时被调用
SqlSourceBuilder实际只是作为封装的启动类或初始化类,其主要操作通过成员内部类ParameterMappingTokenHandler执行
它返回一个StaticSqlSource
表达式解析(ParameterExpression)
已知Mybatis中通过#{表达式}来插入请求的参数,一般情况下我们仅仅插入单一的字符串值作为请求参数,但实际上mybatis还支持更多表达式功能;如下
#{age,javaType=int,jdbcType=NUMERIC,typeHandler=MyTypeHandler}#{height,javaType=double,jdbcType=NUMERIC,numericScale=2}: numericScale用于指定小数点后面几位
ParameterExpression时表达式的解析类同事也是解析后的数据封装类,它继承了HashMap以key-Value的形式存解析出来的表达式
表达式解析类通过ParameterExpression.java解析,具体分析如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 package org.learn.mybatis;import org.junit.Test;import java.util.HashMap;import java.util.Iterator;import java.util.Set;public class ParameterExpression extends HashMap <String, String> {private static final long serialVersionUID = -2417552199605158680L ;public ParameterExpression () {@Test public void testParamExpression () throws Exception {String s = " middleInitial, mode=OUT, jdbcType=STRUCT, jdbcTypeName=MY_TYPE, resultMap=departmentResultMap" ;this .parse(s);this .entrySet();while (iterator.hasNext()) {"key=" + next.getKey() + ",value=" + next.getValue());private void parse (String expression) throws Exception {int p = this .skipWS(expression, 0 );if (expression.charAt(p) == '(' ) {this .expression(expression, p + 1 );else {this .property(expression, p);private void expression (String expression, int left) throws Exception {int match = 1 ;int right;for (right = left + 1 ; match > 0 ; ++right) {if (expression.charAt(right) == ')' ) {else if (expression.charAt(right) == '(' ) {this .put("expression" , expression.substring(left, right - 1 ));this .jdbcTypeOpt(expression, right);private void property (String expression, int left) throws Exception {if (left < expression.length()) {int right = this .skipUntil(expression, left, ",:" );this .put("property" , this .trimmedStr(expression, left, right));this .jdbcTypeOpt(expression, right);private int skipWS (String expression, int p) {for (int i = p; i < expression.length(); ++i) {if (expression.charAt(i) > ' ' ) {return i;return expression.length();private int skipUntil (String expression, int p, String endChars) {for (int i = p; i < expression.length(); ++i) {char c = expression.charAt(i);if (endChars.indexOf(c) > -1 ) {return i;return expression.length();private void jdbcTypeOpt (String expression, int p) throws Exception {this .skipWS(expression, p);if (p < expression.length()) {if (expression.charAt(p) == ':' ) {this .jdbcType(expression, p + 1 );else {if (expression.charAt(p) != ',' ) {throw new Exception ("Parsing error in {" + expression + "} in position " + p);this .option(expression, p + 1 );private void jdbcType (String expression, int p) throws Exception {int left = this .skipWS(expression, p);int right = this .skipUntil(expression, left, "," );if (right > left) {this .put("jdbcType" , this .trimmedStr(expression, left, right));this .option(expression, right + 1 );else {throw new Exception ("Parsing error in {" + expression + "} in position " + p);private void option (String expression, int p) {int left = this .skipWS(expression, p);if (left < expression.length()) {int right = this .skipUntil(expression, left, "=" );String name = this .trimmedStr(expression, left, right);1 ;this .skipUntil(expression, left, "," );String value = this .trimmedStr(expression, left, right);this .put(name, value);this .option(expression, right + 1 );private String trimmedStr (String str, int start, int end) {while (str.charAt(start) <= ' ' ) {while (str.charAt(end - 1 ) <= ' ' ) {return start >= end ? "" : str.substring(start, end);
表达式封装(ParameterMappingTokenHandler) 表达式识别 表达式识别通过工具类GenericTokenParser来实现,该工具类会根据参数识别需要的表达式,并自动调用handler中的handleToken()
表达式封装 该方法会将表达式替换为?以便后续sql注入,具体的封装在buildParameterMapping()中
方法具体内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 private ParameterMapping buildParameterMapping (String content) {String property = propertiesMap.get("property" );if (metaParameters.hasGetter(property)) { else if (typeHandlerRegistry.hasTypeHandler(parameterType)) {else if (JdbcType.CURSOR.name().equals(propertiesMap.get("jdbcType" ))) {else if (property == null || Map.class.isAssignableFrom(parameterType)) {else {MetaClass metaClass = MetaClass.forClass(parameterType, configuration.getReflectorFactory());if (metaClass.hasGetter(property)) {else {Builder builder = new ParameterMapping .Builder(configuration, property, propertyType);String typeHandlerAlias = null ;for (Map.Entry<String, String> entry : propertiesMap.entrySet()) {String name = entry.getKey();String value = entry.getValue();if ("javaType" .equals(name)) {else if ("jdbcType" .equals(name)) {else if ("mode" .equals(name)) {else if ("numericScale" .equals(name)) {else if ("resultMap" .equals(name)) {else if ("typeHandler" .equals(name)) {else if ("jdbcTypeName" .equals(name)) {else if ("property" .equals(name)) {else if ("expression" .equals(name)) {throw new BuilderException ("Expression based parameters are not supported yet" );else {throw new BuilderException ("An invalid property '" + name + "' was found in mapping #{" + content + "}. Valid properties are " + PARAMETER_PROPERTIES);if (typeHandlerAlias != null ) {return builder.build();
注意:ParameterMapping从始至终中只存放了查询表达式’#{value}‘,类型,类型转换器等特性,并未封装请求参数的值
Sql执行 通过mybatis主架构得知,mybatis的具体语句执行需要通过执行器Executor语句执行
以查询为例,以下是SimpleExecutor中调用查询方法的代码,可见已经传入了执行sql所需要的所有变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public <E> List<E> doQuery (MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {Statement stmt = null ;try {Configuration configuration = ms.getConfiguration();StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);return handler.query(stmt, resultHandler);finally {private Statement prepareStatement (StatementHandler handler, Log statementLog) throws SQLException {Connection connection = getConnection(statementLog);return stmt;
可见sql的执行过程在handler类的辅助下变得简单,接下来具体分析这个handler类
StatementHandler(statement辅助类) 初始化 StatementHandler初始化 通过Configuration对象的newStatementHandler()实现
1 2 3 4 5 6 7 public StatementHandler newStatementHandler (Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {StatementHandler statementHandler = new RoutingStatementHandler (executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);return statementHandler;
可见核心是RoutingStatementHandler类的初始化
RoutingStatementHandler 观察这个类不难发现其实他是一个任务委派者,而真正执行的是下述代码中的三种Handler。
SimpleStatementHandler
PreparedStatementHandler
CallableStatementHandler
委派模式的核心是成员变量delegate(delegete将指向具体的委派者),并且委派者同被委派者们都实现了StatementHandler接口,因此需要实现接口中的方法,而这些方法实际的实现都是通过delegate来调用对应的同名方法;具体参考下例中的委派案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 private final StatementHandler delegate;public RoutingStatementHandler (Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {switch (ms.getStatementType()) {case STATEMENT:new SimpleStatementHandler (executor, ms, parameter, rowBounds, resultHandler, boundSql);break ;case PREPARED:new PreparedStatementHandler (executor, ms, parameter, rowBounds, resultHandler, boundSql);break ;case CALLABLE:new CallableStatementHandler (executor, ms, parameter, rowBounds, resultHandler, boundSql);break ;default :throw new ExecutorException ("Unknown statement type: " + ms.getStatementType());public ParameterHandler getParameterHandler () {return delegate.getParameterHandler();
PreparedStatementHandler 根据上述SimpleExecutor的doQuary()方法及后续分析得知,jdbc的api调用分为一下几个阶段,通过以下代码分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public class PreparedStatementHandler extends BaseStatementHandler {public PreparedStatementHandler (Executor executor, MappedStatement mappedStatement, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {super (executor, mappedStatement, parameter, rowBounds, resultHandler, boundSql);@Override public <E> List<E> query (Statement statement, ResultHandler resultHandler) throws SQLException {PreparedStatement ps = (PreparedStatement) statement;return resultSetHandler.handleResultSets(ps);@Override protected Statement instantiateStatement (Connection connection) throws SQLException {String sql = boundSql.getSql();if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {if (keyColumnNames == null ) {return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);else {return connection.prepareStatement(sql, keyColumnNames);else if (mappedStatement.getResultSetType() == ResultSetType.DEFAULT) {return connection.prepareStatement(sql);else {return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);@Override public void parameterize (Statement statement) throws SQLException {
上述代码有两个疑问
parameterHandler和resultSetHandler这两个处理器来自何处?
它们在PreparedStatementHandler的父类BaseStatementHandler构造函数中处生成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 protected BaseStatementHandler (Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {this .configuration = mappedStatement.getConfiguration();this .executor = executor;this .mappedStatement = mappedStatement;this .rowBounds = rowBounds;this .typeHandlerRegistry = configuration.getTypeHandlerRegistry();this .objectFactory = configuration.getObjectFactory();if (boundSql == null ) { this .boundSql = boundSql;this .parameterHandler = configuration.newParameterHandler(mappedStatement, parameterObject, boundSql);this .resultSetHandler = configuration.newResultSetHandler(executor, mappedStatement, rowBounds, parameterHandler, resultHandler, boundSql);
ParameterHandler 初始化 ParameterHandler默认只有一种实现DefaultParameterHandler,它在configuration对象的方法中创建
1 2 3 4 5 6 7 public ParameterHandler newParameterHandler (MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql);return parameterHandler;
注入参数 核心方法分析如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 @Override public void setParameters (PreparedStatement ps) {"setting parameters" ).object(mappedStatement.getParameterMap().getId());if (parameterMappings != null ) {for (int i = 0 ; i < parameterMappings.size(); i++) {ParameterMapping parameterMapping = parameterMappings.get(i);if (parameterMapping.getMode() != ParameterMode.OUT) {String propertyName = parameterMapping.getProperty();if (boundSql.hasAdditionalParameter(propertyName)) { else if (parameterObject == null ) {null ;else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {else {MetaObject metaObject = configuration.newMetaObject(parameterObject);TypeHandler typeHandler = parameterMapping.getTypeHandler();JdbcType jdbcType = parameterMapping.getJdbcType();if (value == null && jdbcType == null ) {try {1 , value, jdbcType);catch (TypeException | SQLException e) {throw new TypeException ("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
可以看到ParameterHandler仅仅是通过#{value}表达式获取到了实际请求参数中的值,并解析了ParameterMapping中配置
TypeHandler mybatis默认为这个接口实现了N多种实现类(实现了大部分传统数据类型),并初始化了它们,但实际用哪种需要用户指定。例如在表达式中写入#{value,javaType="int"};当用户未指定时则默认使用实现类UnknownTypeHandler ,指定流程在ParameterMapping对象构造时完成;
TypeHandler和它的子类基于模板方法模式实现
BaseTypeHandler(模板方法类) TypeHandler有一个抽象类BaseTypeHandler,它实现了setParameter方法,该方法将作为模板成为TypeHandler的该方法的唯一实现;相应的模板方法中自然会调用元素方法(由具体的TypeHandler实现类实现,而这些元素方法根据不的实现类实现了不同的功能,如:本例中根据情况对不同类型的请求参数为Statement对象赋值);以上是对模板方法模式的描述
模板方法代码如下,仅仅只有几个判断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public void setParameter (PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException {if (parameter == null ) {if (jdbcType == null ) {throw new TypeException ("JDBC requires that the JdbcType must be specified for all nullable parameters." );try {catch (SQLException e) {throw new TypeException ("Error setting null for parameter #" + i + " with JdbcType " + jdbcType + " . " "Try setting a different JdbcType for this parameter or a different jdbcTypeForNull configuration property. " "Cause: " + e, e);else {try {catch (Exception e) {throw new TypeException ("Error setting non null for parameter #" + i + " with JdbcType " + jdbcType + " . " "Try setting a different JdbcType for this parameter or a different configuration property. " "Cause: " + e, e);
UnknownTypeHandler(默认Handler) 作为默认实现,当不知道或没有请求参数类型时,使用该Handler;它实际是一个路由,用来动态发现传入的数据是什么类型
有一个核心变量typeHandlerRegistrySupplier 保存了所有基本类型Handler的map集合 (实际这些集合存储在TypeHandlerRegistry类中)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class UnknownTypeHandler extends BaseTypeHandler <Object> {private static final ObjectTypeHandler OBJECT_TYPE_HANDLER = new ObjectTypeHandler ();private final Configuration config;private final Supplier<TypeHandlerRegistry> typeHandlerRegistrySupplier;public UnknownTypeHandler (Configuration configuration) {this .config = configuration;this .typeHandlerRegistrySupplier = configuration::getTypeHandlerRegistry;public void setNonNullParameter (PreparedStatement ps, int i, Object parameter, JdbcType jdbcType) throws SQLException {TypeHandler handler = resolveTypeHandler(parameter, jdbcType);private TypeHandler<?> resolveTypeHandler(Object parameter, JdbcType jdbcType) {if (parameter == null ) {else {if (handler == null || handler instanceof UnknownTypeHandler) {return handler;
篇幅限制不介绍TypeHandlerRegistry类和getTypeHandler()方法了,简单说明一下
TypeHandlerRegistry注册了所有的TypeHandler并通过Map集合管理,key为对象Type类型,value为
getTypeHandler()具体操作分以下几步
根据要注入的parameter对象的反射类型,从集合中获取对应的jdbcTypeHandler的map(注意,是map)
如果有jdbc类型设置则从这个map中获取,如果没有则根据要注入的parameter对象的类型从map中获取
下述代码是实际handler执行的statement参数的设置代码
1 2 3 4 public void setNonNullParameter (PreparedStatement ps, int i, String parameter, JdbcType jdbcType) throws SQLException {
辅助类 表达式识别(GenericTokenParser) 表达式工具类只有一个方法,大致逻辑有三步
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class GenericTokenParser {private final String openToken;private final String closeToken;private final TokenHandler handler;public GenericTokenParser (String openToken, String closeToken, TokenHandler handler) {this .openToken = openToken;this .closeToken = closeToken;this .handler = handler;public String parse (String text) {
表达式调用逻辑可参考ParameterMappingTokenHandler
参数处理类(TypeHandler) TypeHandler用于辅助注入请求参数并指定jdbc的type类型
类型注册中心(TypeHandlerRegistry)
TypeHandlerRegistry跟随configuration对象生成,作为它的成员变量伴随configuration终生
private final Map<Type, Map<JdbcType, TypeHandler<?>>> typeHandlerMap = new ConcurrentHashMap<>();
向typeHandlerMap集合放置数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private void register (Type javaType, JdbcType jdbcType, TypeHandler<?> handler) {if (javaType != null ) {if (map == null || map == NULL_TYPE_HANDLER_MAP) {new HashMap <>();